گوگل میں کتنے پی ایس ہیں؟ گوگل کے مطابق، دو ہیں.
لفظ 'پوپ' میں "بالکل 1 'r' بھی ہے،" گوگل کا AI جائزہ کہتا ہے، نیز صحافت کے لفظ میں دو 'd'، پھر بھی اس کے ہجے ہیں: j-o-u-r-n-a-d-i-s-m۔ گوگل نے کم از کم اس بات کی نشاندہی کی کہ امریکی صدر کے آخری نام میں ایک پی ہے، لیکن اس کی ہجے t-r-p-u-m۔
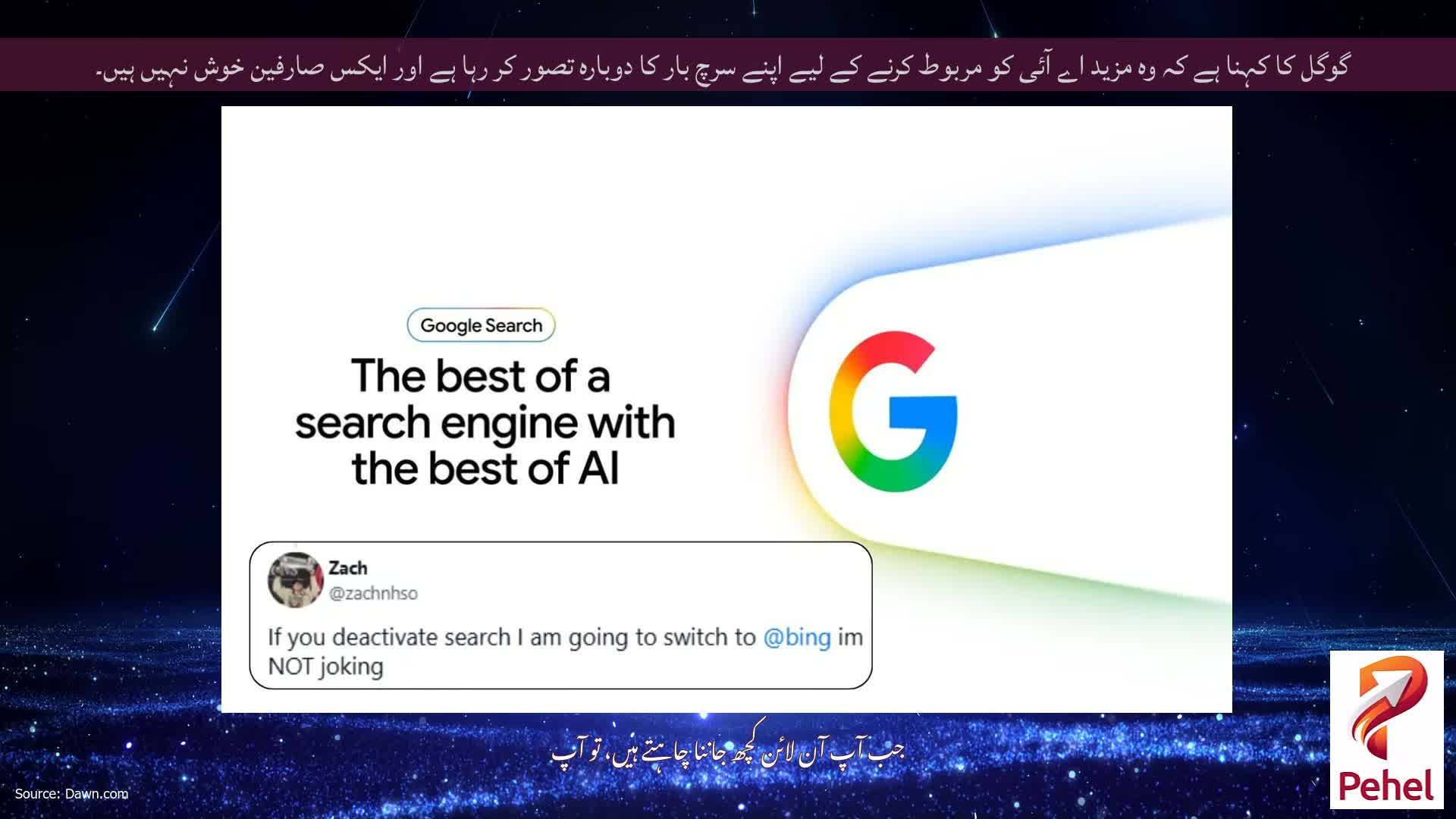
آپ کو یہ پیشین گوئی کرنے کے لیے نبی بننے کی ضرورت نہیں تھی کہ گوگل کا AI-فارورڈ سرچ اوور ہال خراب ہونے والا ہے۔ ہم نے یہ پہلے بھی کیا ہے۔ پہلی بار جب گوگل نے تلاش میں AI جائزہ شامل کیا، یہ خصوصیت The Onion اور Reddit کی طنزیہ پوسٹس کا حوالہ دیتے ہوئے ختم ہوئی، جس میں لوگوں کو پتھر کھانے اور اپنے پیزا پر گوند لگانے کا مشورہ دیا گیا۔
اس بار، جیسا کہ گوگل اپنے 29 سالہ پرانے فلیگ شپ پراڈکٹ کا مرکز تخلیقی AI بنانے کے عزم کو دوگنا کرتا ہے، اسے ٹھوکر کھاتے ہوئے دیکھنا کوئی حیران کن بات نہیں ہے۔
گوگل اپنے پورے سرچ انجن کو اس btw pic.twitter.com/PIR4llFhiV میں تبدیل کر رہا ہے۔
گوگل نے ایک ای میل بیان میں TechCrunch کو بتایا، "لفظوں میں گنتی LLMs کے لیے ایک معروف چیلنج رہا ہے، اور ہم اس خاص مسئلے کو حل کرنے کے لیے کام کر رہے ہیں۔"
املا کی یہ بنیادی غلطیاں واقف معلوم ہو سکتی ہیں۔ LLMs، مصنوعی ذہانت کی قسم جو چیٹ بوٹس اور دوسرے ٹیکسٹ جنریٹرز کو طاقت دیتی ہے، ہجے کو سمجھنے کے لیے نہیں بنائے گئے ہیں۔ یہ برسوں سے چل رہا ہے کہ جب بھی کوئی کمپنی کسی نئے AI ماڈل کی نقاب کشائی کرتی ہے تو آپ کو اس سے پوچھنا چاہیے کہ لفظ اسٹرابیری میں کتنے 'r' ہیں۔ یہ AI ماڈلز - جو سیکنڈوں میں ایک ایپ کو کوڈ کر سکتے ہیں، یا ایسے مسائل کو حل کر سکتے ہیں جنہوں نے ریاضی دانوں کو دہائیوں سے اسٹمپ کر رکھا ہے - ہجے میں ایک کنڈرگارٹنر کی طرح اچھے ہیں۔
گوگل کے AI جائزہ کی پریشانیاں اگرچہ احمقانہ ہجے کی غلطیوں سے بالاتر ہیں۔ گوگل نے پچھلے ہفتے سے پہلے ہی ایک مسئلہ تیار کیا تھا جس میں لفظ "نظر انداز" کو تلاش کرنے سے وہی نکلے گا جو لفظ کی لغت کی تعریف کی طرح نظر آتا ہے، صرف اس تعریف کو دکھایا گیا تھا، "سمجھ گیا۔ جب بھی آپ کے پاس کوئی نیا اشارہ یا سوال ہو تو مجھے بتائیں!" لیکن ہجے کی یہ غلطیاں دل لگی رہی ہیں کیونکہ ان کو ختم کرنا بہت مشکل ہے۔
جیسا کہ محققین نے پہلے وضاحت کی ہے کہ جب ہم نے ہجے کے ان مسائل کے بارے میں پوچھا ہے تو، AI جملوں کو الفاظ اور حروف سے بنی زبان کی اکائیوں کے طور پر نہیں سمجھتا ہے۔ بہت سے LLMs ٹرانسفارمرز ماڈلز پر بنائے گئے ہیں، جو متن کو ٹوکنز میں توڑ دیتے ہیں، جو ماڈل کے لحاظ سے مکمل الفاظ، حرف یا حروف ہو سکتے ہیں۔ انسان کی مرضی کی طرح "پڑھنے" کے بجائے، AI متن کو خود کی عددی نمائندگی میں تبدیل کرتا ہے، جو پھر AI کو منطقی ردعمل کے ساتھ آنے میں مدد کرنے کے لیے سیاق و سباق کے مطابق بنائے جاتے ہیں۔
"ایل ایل ایم اس ٹرانسفارمر فن تعمیر پر مبنی ہیں، جو خاص طور پر متن کو نہیں پڑھ رہا ہے۔ جب آپ پرامپٹ داخل کرتے ہیں تو کیا ہوتا ہے کہ اس کا انکوڈنگ میں ترجمہ کیا جاتا ہے،" میتھیو گوزڈیال، ایک AI محقق اور البرٹا یونیورسٹی کے اسسٹنٹ پروفیسر نے TechCrunch کو بتایا۔ "جب یہ لفظ 'the' کو دیکھتا ہے، تو اس میں 'the' کے معنی کا یہ ایک انکوڈنگ ہوتا ہے، لیکن یہ 'T'، 'H'، 'E' کے بارے میں نہیں جانتا۔"
ٹوکن پر مبنی فن تعمیر جو LLMs کو طاقت دیتا ہے جیسے Google کا AI جائزہ فطری طور پر محدود ہے، اور محققین پر امید نہیں ہیں کہ وہ املا کے مسئلے کو حل کر سکتے ہیں۔
شمال مشرقی یونیورسٹی میں بڑے لینگویج ماڈل کی تشریح کا مطالعہ کرنے والے پی ایچ ڈی کے طالب علم شیریڈن فیوچٹ، شیریڈن فیوچٹ، ایک پی ایچ ڈی کے طالب علم، جو کہ ایک زبان کے ماڈل کے لیے بالکل کیا ہونا چاہیے، اس سوال کے بارے میں سوچنا مشکل ہے، اور یہاں تک کہ اگر ہم انسانی ماہرین کو ایک کامل ٹوکن ذخیرہ الفاظ پر متفق کرنے کے لیے حاصل کر لیتے ہیں، تب بھی ماڈلز کو چیزوں کو مزید 'ٹکڑا' کرنا مفید معلوم ہوگا۔" "میرا اندازہ یہ ہوگا کہ اس قسم کی دھندلاپن کی وجہ سے کامل ٹوکنائزر جیسی کوئی چیز نہیں ہے۔"
یہ ضروری نہیں کہ محققین کے ذہنوں پر کوئی فوری مسئلہ ہو، کیونکہ LLMs کی افادیت ان کے ہجے کرنے کی صلاحیت میں نہیں آتی ہے۔ لیکن یہ صریح ناکامیاں ہمیں یہ یاد رکھنے میں مدد کرتی ہیں کہ AI کامل نہیں ہے، یہاں تک کہ اگر یہ کبھی کبھی ہماری سمجھ سے باہر ایک تمام جاننے والی طاقت کی طرح لگتا ہے۔ ہم AI آؤٹ پٹس پر ان کی درستگی کی دو بار جانچ کیے بغیر ان پر اندھا اعتماد نہیں کر سکتے۔