په ګوګل کې څومره Ps دي؟ د ګوګل په وینا، دوه شتون لري.
د 'پوپ' په کلمه کې "په سمه توګه 1 'r' هم شتون لري، د ګوګل AI عمومي کتنه وايي، په بیله بیا د ژورنالیزم په کلمه کې دوه 'd'، بیا هم دا یې لیکلی: j-o-u-r-n-a-d-i-s-m. ګوګل لږترلږه په ګوته کړه چې د متحده ایالاتو د ولسمشر په وروستي نوم کې یو P شتون لري ، مګر دا یې د t-r-p-u-m په توګه لیکلی.
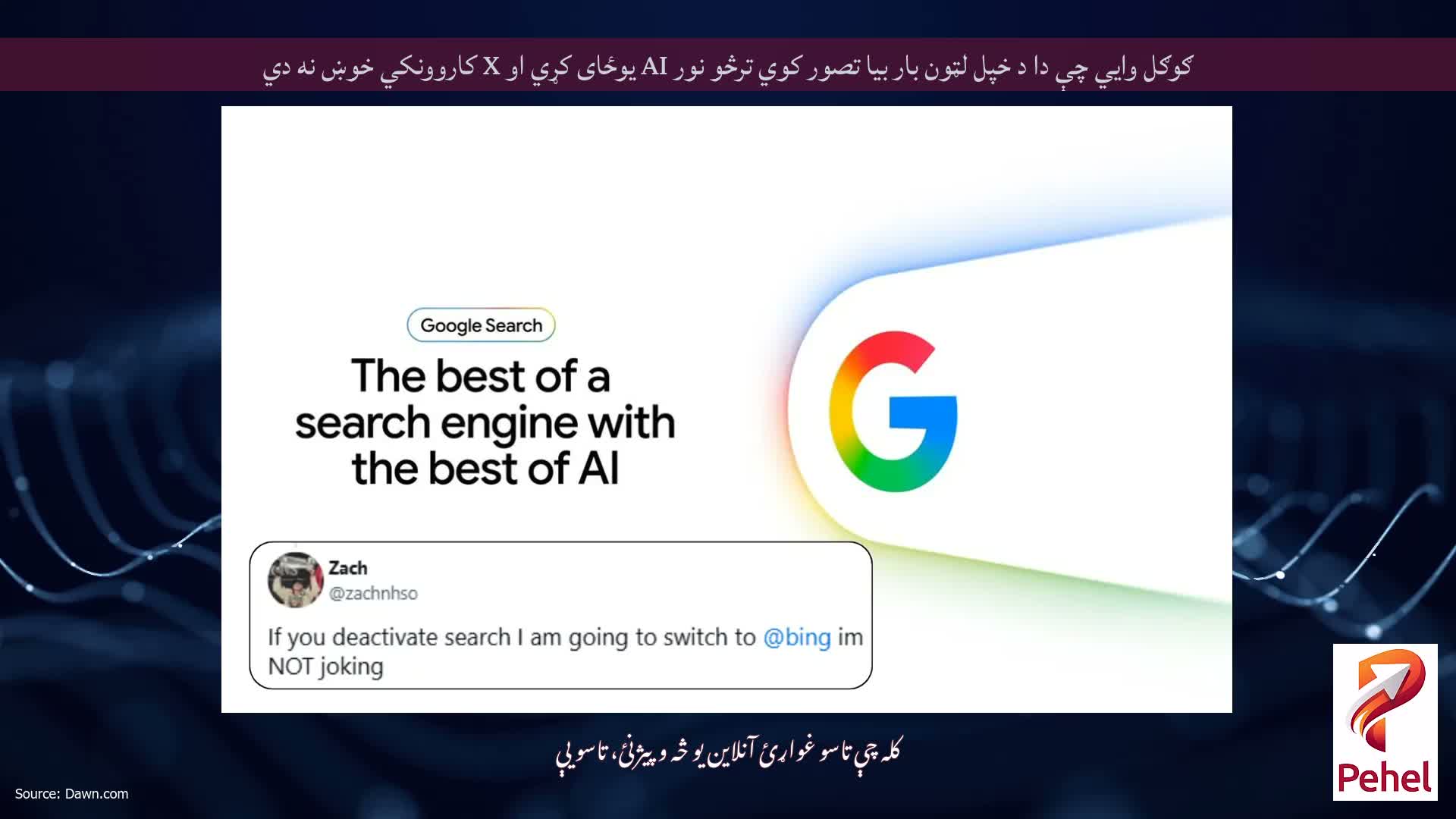
تاسو اړتیا نلرئ یو پیغمبر شئ چې وړاندوینه وکړئ چې د ګوګل د AI - فارورډ لټون بیارغونه په خراب ډول پرمخ ځي. موږ مخکې دا کار کړی دی. لومړی ځل چې ګوګل په لټون کې د AI عمومي نظرونه اضافه کړل، دا فیچر د پیاز او ریډیټ څخه د طنزیه پوسټونو په حواله پای ته ورسیده، خلکو ته یې مشوره ورکړه چې ډبرې وخوري او په پیزا کې چپک واچوي.
دا ځل شاوخوا، لکه څنګه چې ګوګل د خپل 29 کلن پرچم بردار محصول د تولیدي AI د مرکزي برخې جوړولو لپاره د خپلې ژمنې دوه چنده کوي ، دا د حیرانتیا خبره نده چې دا یې ودریږي.
ګوګل دې btw pic.twitter.com/PIR4llFhiV ته خپل ټول د لټون انجن ترمیم کوي
"د کلمو دننه شمیرل د LLMs لپاره یوه پیژندل شوې ننګونه وه، او موږ د دې ځانګړې مسلې د حل لپاره کار کوو،" ګوګل په یوه بریښنالیک بیان کې TechCrunch ته وویل.
دا لومړني املا غلطۍ ممکن پیژندل شوي ښکاري. LLMs، د مصنوعي استخباراتو ډول چې د چیټ بوټونو او نورو متن - جنریټرونو ځواک ورکوي، د املا د پوهیدو لپاره ندي جوړ شوي. دا د کلونو لپاره روانه ټوکه وه چې هرکله چې یو شرکت د AI نوی ماډل افشا کړي، تاسو باید وپوښتئ چې د سټرابیري په کلمه کې څومره 'r' دي. دا AI ماډلونه - کوم چې کولی شي په ثانیو کې یو اپلیکیشن کوډ کړي، یا هغه ستونزې حل کړي چې د لسیزو راهیسې یې ریاضي پوهان ستومانه کړي - په املا کې د وړکتون په څیر ښه دي.
د ګوګل د AI عمومي لید ستونزې که څه هم له احمقانه املا غلطیو هاخوا ته رسي. ګوګل لا دمخه د تیرې اونۍ څخه یوه مسله جوړه کړې چې په کې د "بې پامۍ" کلمې لټون کول به هغه څه ترلاسه کړي چې د کلمې د لغت تعریف په څیر ښکاري، یوازې تعریف داسې ښودل شوی و، "پوه شوی. هرکله چې تاسو نوې پوښتنه یا پوښتنه لرئ ما ته خبر راکړئ!" مګر دا املا غلطۍ په زړه پوري پاتې دي ځکه چې دوی له مینځه وړل خورا ستونزمن دي.
لکه څنګه چې څیړونکو دمخه تشریح کړی کله چې موږ د دې املا د خنډونو په اړه وپوښتل، AI جملې د ژبې د واحدونو په توګه نه پیژني چې د کلمو او تورو څخه جوړ شوي. ډیری LLMs د ټرانسفارمر ماډلونو باندې جوړ شوي، کوم چې متن په ټوکونو کې ماتوي، کوم چې د ماډل پورې اړه لري، بشپړ کلمې، نحو، یا لیکونه کیدی شي. د انسان په څیر د "لوستلو" پرځای، AI متن د خپل ځان په شمیري نمایندګیو بدلوي، کوم چې بیا د AI سره د منطقي ځواب سره د مرستې لپاره د شرایطو سره تړاو لري.
"LLMs د دې ټرانسفارمر جوړښت پراساس دي ، کوم چې په حقیقت کې متن نه لوستل کیږي. څه پیښیږي کله چې تاسو پرامپټ داخل کړئ دا دی چې دا په کوډ کولو کې ژباړل کیږي ،" میتیو ګزډیال ، د البرټا پوهنتون کې د AI څیړونکی او معاون پروفیسور ، ټیک کرنچ ته وویل. "کله چې دا د 'The' کلمه وګوري، دا د 'T'، 'H'، 'E' په اړه نه پوهیږي، دا یو کوډ لري چې د 'The' معنی لري، مګر دا د 'T'،' H،' E' په اړه نه پوهیږي.
د ټوکن پراساس جوړښت چې د ګوګل AI عمومي لید په څیر LLMs ته ځواک ورکوي په طبیعي ډول محدودیت لري ، او څیړونکي خوشبین ندي چې دوی کولی شي د املا ستونزه حل کړي.
"دا یو ډول ستونزمن کار دی چې د دې پوښتنې په اړه پوهیدل چې واقعیا د یوې ژبې ماډل لپاره 'کلمه' باید څه وي، او حتی که موږ د انساني متخصصینو سره د سم ټکن لغتونو په اړه موافقه وکړو، ماډلونه به بیا هم د شیانو د "ټوټو" کولو لپاره نور هم ګټور وي،" شیریډان فیوچټ، د پی ایچ ډی زده کونکي چې په شمال ختیځ پوهنتون کې د لوی ژبې ماډل تفسیر مطالعه کوي، ټیکچر ته وویل. "زما اټکل به دا وي چې د دې ډول مبهمۍ له امله د بشپړ ټوکنائزر په څیر هیڅ شی شتون نلري."
دا اړینه نه ده چې د څیړونکو په ذهنونو کې یوه عاجل ستونزه وي، ځکه چې د LLMs کارول د دوی د املا کولو ظرفیت کې نه راځي. مګر دا ښکاره ناکامۍ موږ سره مرسته کوي چې په یاد ولرئ چې AI کامل نه دی، حتی که دا ځینې وختونه زموږ د پوهاوي څخه بهر د ټول پوهه ځواک په څیر ښکاري. موږ نشو کولی د AI محصولاتو د دقت دوه ځله چیک کولو پرته په ړوند ډول باور وکړو.