گوگل ۾ ڪيترا پي ايس آهن؟ گوگل جي مطابق، اتي ٻه آهن.
هتي پڻ آهي "بلڪل 1 'ر' لفظ 'پوپ' ۾،" گوگل جو AI جائزو چوي ٿو، انهي سان گڏ ٻه 'd' لفظ صحافت ۾، اڃا تائين ان کي اسپيل ڪيو: j-o-u-r-n-a-d-i-s-m. گوگل گهٽ ۾ گهٽ سڃاڻپ ڪئي ته آمريڪي صدر جي آخري نالي ۾ هڪ پي آهي، پر ان کي ٽي-ر-پي-يو-م طور اسپيل ڪيو.
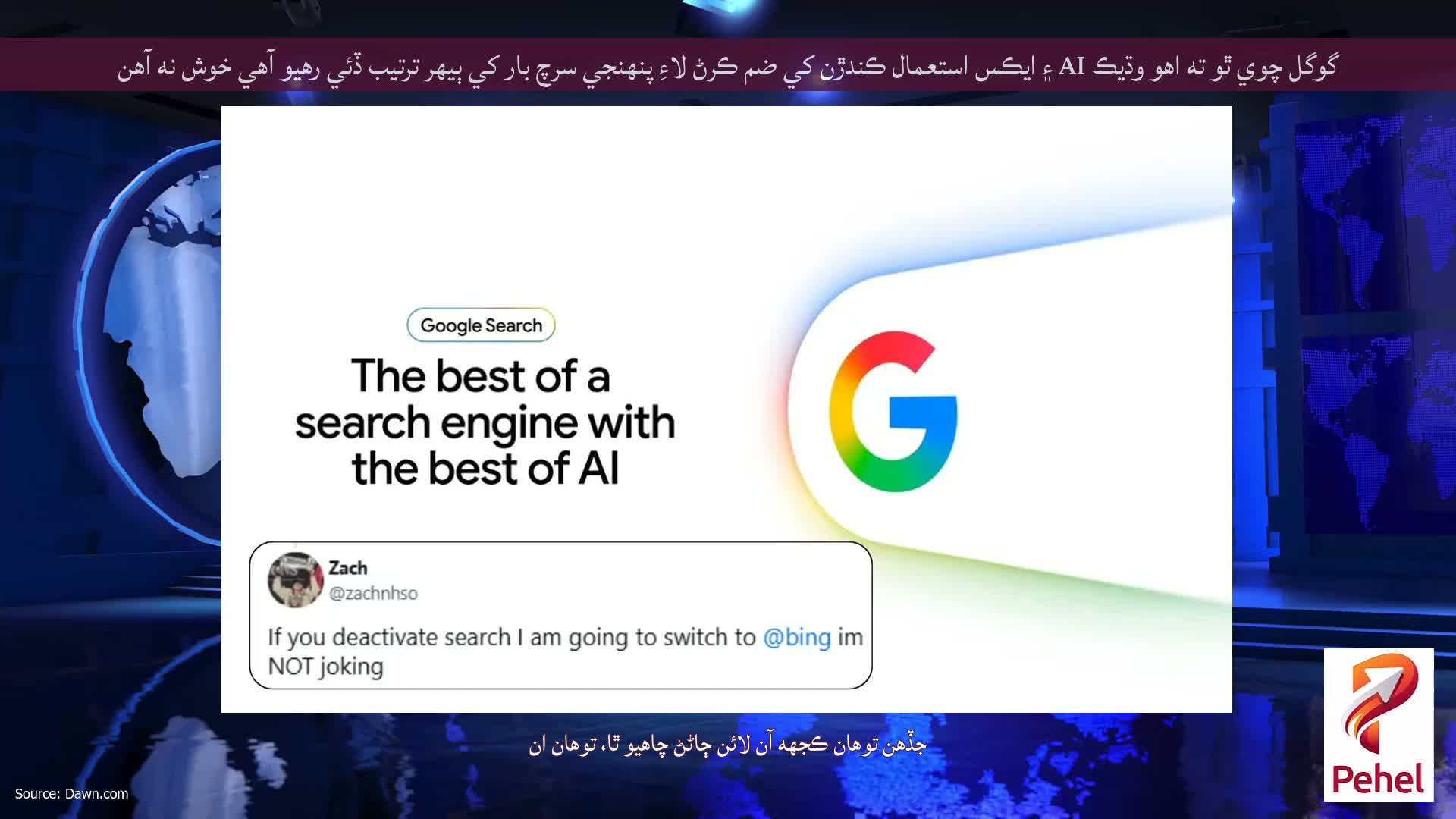
توهان کي اڳڪٿي ڪرڻ لاءِ نبي هجڻ جي ضرورت نه هئي ته گوگل جي AI-فارورڊ سرچ اوور هال خراب ٿيڻ وارو هو. اسان هن کان اڳ ڪيو آهي. پهريون ڀيرو گوگل سرچ ۾ AI Overviews شامل ڪيو، فيچر ختم ٿي ويو The Onion ۽ Reddit کان طنزيه پوسٽن جو حوالو ڏيندي، ماڻهن کي صلاح ڏني ته پٿر کائڻ ۽ انهن جي پيزا تي گلو لڳايو.
هن ڀيري، جيئن گوگل پنهنجي 29 سال پراڻي فليگ شپ پراڊڪٽ جي پيداواري AI کي مرڪز بڻائڻ لاءِ پنهنجي وابستگي تي ٻيڻو ڪري ٿو، اهو ڏسڻ ۾ حيرت جي ڳالهه ناهي.
گوگل پنهنجي پوري سرچ انجڻ کي هن btw ۾ تبديل ڪري رهيو آهي pic.twitter.com/PIR4llFhiV
"لفظن ۾ ڳڻڻ LLMs لاءِ هڪ سڃاتل چئلينج رهيو آهي، ۽ اسان هن خاص مسئلي کي حل ڪرڻ لاءِ ڪم ڪري رهيا آهيون،" گوگل هڪ اي ميل ٿيل بيان ۾ TechCrunch کي ٻڌايو.
اهي بنيادي اسپيل غلطيون شايد واقف ٿي سگهن ٿيون. LLMs، مصنوعي ذهانت جو هڪ قسم جيڪو چيٽ بوٽس ۽ ٻين ٽيڪسٽ جنريٽر کي طاقت ڏئي ٿو، اسپيلنگ کي سمجهڻ لاءِ ٺهيل نه آهن. اهو ڪيترن سالن کان هلندڙ مذاق رهيو آهي ته جڏهن به ڪا ڪمپني نئين AI ماڊل کي ظاهر ڪري ٿي، توهان کي ان کان پڇڻ گهرجي ته اسٽرابيري لفظ ۾ ڪيترا 'r' آهن. اهي AI ماڊل - جيڪي سيڪنڊن ۾ هڪ ايپ ڪوڊ ڪري سگهن ٿا، يا مسئلا حل ڪري سگهن ٿا جيڪي ڏهاڪن کان رياضي دانن کي اسٽمپ ڪري رهيا آهن - اسپيلنگ ۾ هڪ ڪنڊر گارٽنر جيترو سٺو آهن.
گوگل جي AI جو جائزو وٺڻ واريون پريشانيون بيوقوف اسپيلنگ جي غلطين کان ٻاهر آهن. گوگل اڳ ۾ ئي گذريل هفتي کان هڪ مسئلو پيچ ڪيو آهي جنهن ۾ لفظ "نااهل" ڳولڻ سان لفظ جي ڊڪشنري جي تعريف وانگر نظر ايندي، صرف وصف ڏيکاري وئي هئي، "سمجهيو ويو. مون کي ٻڌايو ته جڏهن توهان وٽ ڪو نئون اشارو يا سوال آهي!" پر اهي اسپيلنگ جون غلطيون دلچسپ رهيون آهن ڇو ته انهن کي ختم ڪرڻ تمام ڏکيو آهي.
جيئن ته محقق اڳ ۾ وضاحت ڪري چڪا آهن جڏهن اسان انهن اسپيلنگ جي ڪنڊرن بابت پڇيو آهي، AI لفظن ۽ اکرن مان ٺهيل ٻولي جي يونٽن جي طور تي جملن کي نٿو سمجهي. ڪيتريون ئي ايل ايل ايم ٽرانسفارمر ماڊل تي ٺهيل آهن، جيڪي متن کي ٽوڪن ۾ ٽوڪن ٿا، جيڪي مڪمل لفظ، اکر، يا اکر ٿي سگهن ٿا، ماڊل تي منحصر ڪري ٿو. انسان وانگر "پڙهڻ" جي بدران، AI متن کي پاڻ جي عددي نمائندگي ۾ تبديل ڪري ٿو، جيڪي پوء AI کي منطقي جواب سان مدد ڪرڻ ۾ مدد ڏيڻ لاء ترتيب ڏنل آهن.
"ايل ايل ايمز هن ٽرانسفارمر آرڪيٽيڪچر تي ٻڌل آهن، جيڪو خاص طور تي اصل ۾ متن نه پڙهي رهيو آهي. ڇا ٿيندو جڏهن توهان هڪ پرامٽ داخل ڪيو ته اهو انڪوڊنگ ۾ ترجمو ڪيو ويو آهي،" ميٿيو گوزڊيل، هڪ AI محقق ۽ البرٽا يونيورسٽي ۾ اسسٽنٽ پروفيسر، TechCrunch کي ٻڌايو. "جڏهن اهو لفظ ڏسي ٿو 'the'، ان ۾ اهو هڪ انڪوڊنگ آهي جيڪو 'the' جو مطلب آهي، پر اهو نه ڄاڻندو آهي 'T،' 'H،' 'E.'
ٽوڪن تي ٻڌل آرڪيٽيڪچر جيڪو LLMs کي طاقت ڏئي ٿو جهڙوڪ گوگل جي AI جو جائزو موروثي طور تي محدود آهي، ۽ محقق پراميد نه آهن ته اهي اسپيلنگ جو مسئلو حل ڪري سگهن ٿا.
”اها ڳالهه سمجهڻ تمام مشڪل آهي ته ڪنهن ٻوليءَ جي ماڊل لاءِ ’لفظ‘ ڇا هجڻ گهرجي، ۽ جيتوڻيڪ اسان وٽ انساني ماهرن کي هڪ مڪمل ٽوڪن لفظ تي اتفاق ڪرڻ لاءِ، ماڊل شايد اڃا به وڌيڪ ڪارائتو ثابت ٿين ها ته شين کي ’چڪ‘ ڪرڻ لاءِ اڃا به وڌيڪ،“ شيريڊان فيوچ، هڪ پي ايڇ ڊي شاگرد جيڪو شمال مشرقي يونيورسٽي ۾ وڏي ٻوليءَ جي ماڊل جي تعبير جو مطالعو ڪري رهيو آهي، TechCruch کي ٻڌايو. ”منهنجو اندازو اهو هوندو ته اهڙي ڪا به شيءِ ڪامل ٽوڪنائزر نه آهي جنهن جي ڪري هن قسم جي مبهميءَ جي ڪري.
اهو ضروري ناهي ته محققن جي ذهنن تي هڪ تڪڙو مسئلو هجي، ڇو ته ايل ايل ايم جي افاديت انهن جي اسپيل ڪرڻ جي صلاحيت ۾ نه ايندي آهي. پر اهي واضح ناڪاميون اسان کي ياد رکڻ ۾ مدد ڪن ٿيون ته AI مڪمل ناهي، جيتوڻيڪ اهو ڪڏهن ڪڏهن اسان جي سمجھ کان ٻاهر هڪ تمام ڄاڻڻ واري طاقت وانگر لڳي سگهي ٿو. اسان AI جي ٻاھرين تي انڌا اعتماد نٿا ڪري سگھون بغير انھن جي درستگي کي ٻيھر جانچڻ جي.